- Home >> Latest News
Characterizing white matter connectivity in Alzheimer's disease and mild cognitive impairment: An automated fiber quantification analysis with two independent datasets
Xuejiao Dou a,b,1, Hongxiang Yao c,1, Feng Feng d, Pan Wang e,f, Bo Zhou d, Dan Jin a,b, Zhengyi Yang a, Jin Li a, Cui Zhao d, Luning Wang d, Ningyu An c, Bing Liu a,b,g, Xi Zhang d*, and Yong Liu a,b,g,*
a Brainnetome Center & National Laboratory of Pattern Recognition, Institute of Automation, Chinese Academy of Sciences, Beijing, Chinab School of Artificial Intelligence, University of Chinese Academy of Sciences, Chinac Department of Radiology, The Second Medical Centre, National Clinical Research Centre for Geriatric Diseases, Chinese PLA General Hospital, Chinad Department of Neurology, The Second Medical Centre, National Clinical Research Centre for Geriatric Diseases, Chinese PLA General Hospital, Chinae Department of Neurology, Tianjin Huanhu Hospital, Tianjin, 300350, Chinaf Department of Neurology, Nankai University Huanhu Hospital, Tianjin, Chinag CAS Center for Excellence in Brain Science and Intelligence Technology, Institute of Automation, Chinese Academyof Sciences, Beijing, China
Abstract
Alzheimer's disease (AD) is a chronic neurodegenerative disease characterized by progressive dementia. Diffusion tensor imaging (DTI) has been widely used to show structural integrity and delineate white matter (WM) degeneration in AD. The automated fiber quantification (AFQ) method is a fully automated approach that can rapidly and reliably identify major WM fiber tracts and evaluate WM properties. The main aim of this study was to assess WM integrity and abnormities in a cohort of patients with amnestic mild cognitive impairment (aMCI) and AD as well as normal controls (NCs). For this purpose, we first used AFQ to identify 20 major WM tracts and assessed WM integrity and abnormalities in a cohort of 120 subjects (39 NCs, 34 aMCI patients and 47 AD patients) in a discovery dataset and 122 subjects (43 NCs, 37 aMCI patients and 42 AD patients) in a replicated dataset. Pointwise differences along WM tracts were identified in the discovery dataset and simultaneously confirmed in the replicated dataset. Next, we investigated the utility of DTI measures along WM tracts as features to distinguish patients with AD from NCs via multilevel cross validation using a support vector machine. Correlation analysis revealed the identified microstructural WM alterations and classification output to be highly associated with cognitive ability in the patient groups, suggesting that they may be a robust biomarker of AD. This systematic study provides a pipeline to examine WM integrity and its potential clinical application in AD and may be useful for studying other neurological and psychiatric disorders.
Key words: Alzheimer's disease; Diffusion-weighted MRI; Tract-specific analysis; White matter; Support vector machine
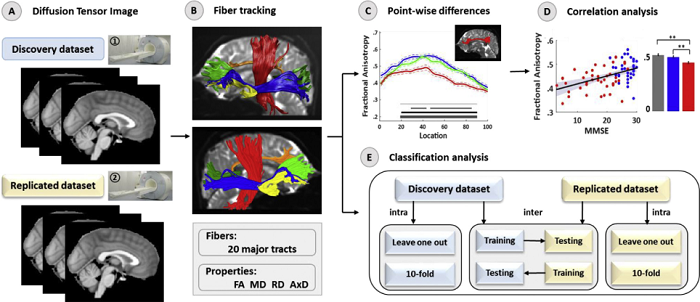
Fig. Sketch of the workflow of the present study. (A) Raw diffusion tensor image. (B) AFQ was used to identify 20 major white matter tracts; for each identified pathway, the FA, MD, RD, and AxD were extracted along the tract. (C) Group-level pointwise analyses of the diffusion metrics across 100 points of each tract were performed. (D) Pearson's correlations between MMSE scores and diffusion properties averaged over the entire length of the white matter tract at each of the major tracts explored in the aMCI and AD groups (p < .05, uncorrected). (E)Intraclassification performance was evaluated by leaveone-out and 10-fold cross validation in the discovery dataset and replicated dataset, respectively. Intersite classification performance was investigated by using the discovery and replicated data as an independent training or test set. Note: The two datasets were acquired from the same department of radiology, and the protocol and parameters used in the MRI examinations were all consistent and differed only in the participants and MR system. We conducted the processing and analysis steps with the discovery dataset for reproducibility and robust results, and the replicated dataset was subjected to the same processes.